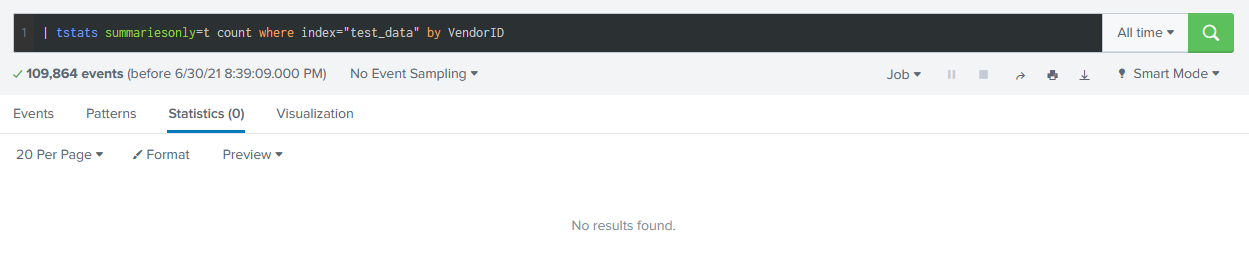
Starting with Splunk 8, the powerful new PREFIX ability has been added, which is a game-changer for speeding up your searches.
But first, a bit of background. Feel free to skip around if you feel confident with this stuff already.
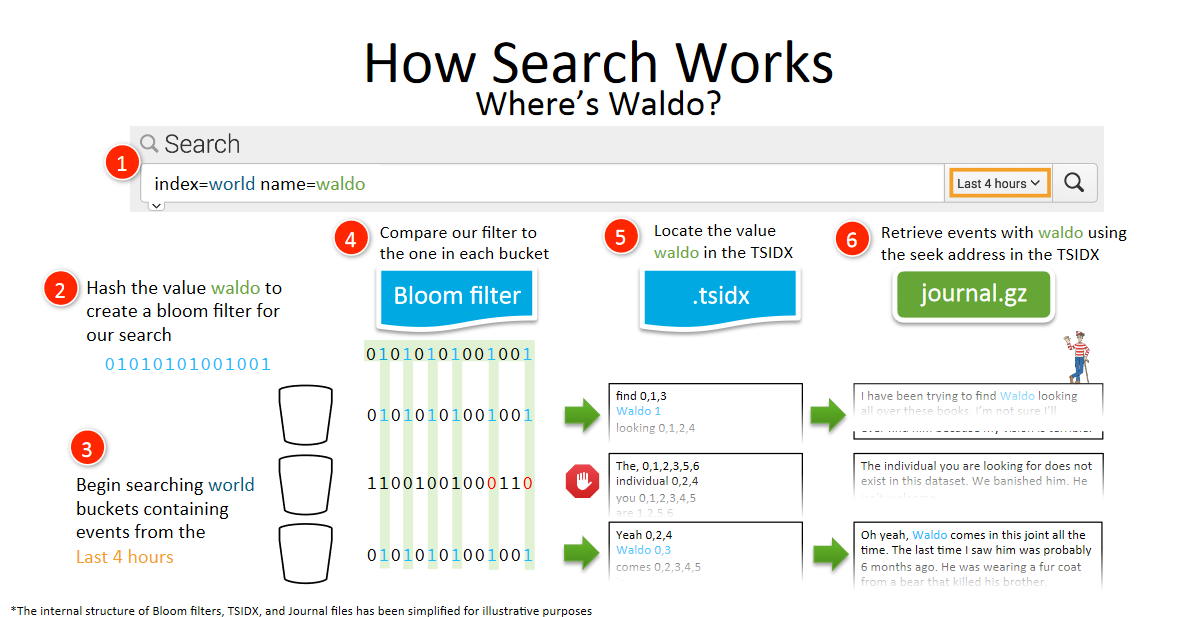
What is a tsidx file, anyway?
At the file system level, data in Splunk is organised into indexes and buckets. Indexes are the highest-level organisation, as separate directories, and each bucket within these holds events in a certain time range. Within each bucket, there are a few files, but the two we care about for this article are the compressed journal file and the tsidx summary.
While the journal file is fairly easy to contextualise - it’s the raw events you can see from Splunk, just compressed to save disk space - the tsidx file can take a little explanation.
Splunk creates the tsidx file to hugely increase search performance. It’s an index of every unique term (ie. words separated by segmenters) found in the journal file, with a pointer to the location(s) of the events where that term is found in the journal.
There are a few other details in the tsidx file that are important, including special indexed fields like index, sourcetype, source, and host, which we’ll cover a bit later. However, to keep things simple, tsidx is a file in the bucket used to summarise events in the compress journal file, so that we can quickly jump to the right event. How can we take advantage of it?
Taking advantage with TERM
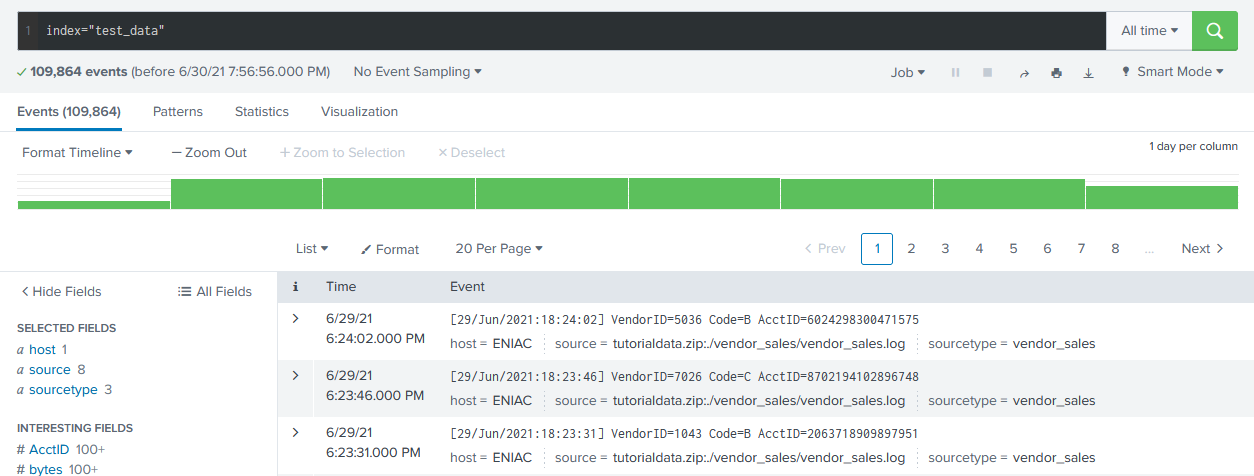
Since that tsidx file contains every unique term in the entire bucket, it’s super useful to find a unique event quickly. For an example, I’ve loaded the Splunk tutorial dataset, which contains about 100,000 events. We can see that a lot of these have some fields in common, like VendorID, Code, and AcctID.
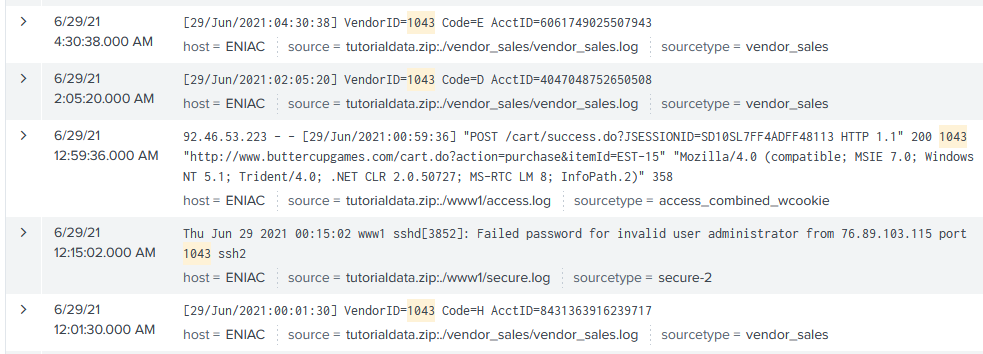
Conventionally, if we wanted to look for a specific vendor, like index="test_data" VendorID="1043", Splunk would start by looking for all events with ‘1043’ in them, before unzipping the journal files and performing field extractions to check against the VendorID field specifically.
We can see that while we were looking for “1043” as our VendorID, there were a few unrelated events that happened to have the same term in them.
Instead, TERM lets us avoid this false positive issue by looking for a more specific value before the journal actions take place. By specifying index="test_data" TERM(VendorID=1043), Splunk eliminates these false positives entries earlier in the search process, reducing the need for the computationally expensive journal actions later on. There are a few other benefits to TERM like bloomfiltering that I won’t go into in this article, but I highly reccomend this great piece by Jamie Talbot explaining some of the details.
For uncommon values across a big dataset - think looking for a specific MD5 hash in millions events over hundreds or thousands of buckets - TERM is stupidly fast compared with conventional searching. It finds needles in big, big haystacks, powered by tsidx files and bloomfilters.
tstats, or how to skip the journal entirely
We’ve established so far that the main priority to optimise searches is to avoid those expensive journal actions that need the full raw events. The more we can leverage the fast tsidx file, the better.
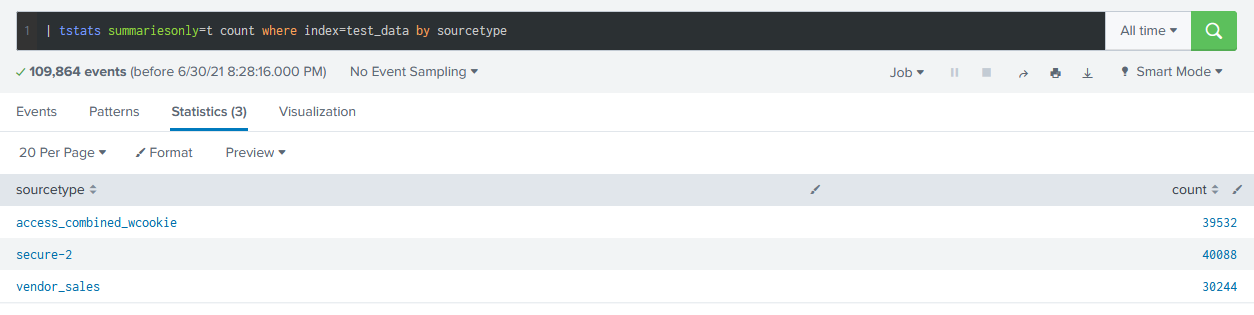
What if we had a fairly simple use case, like counting the number of events in an index by the sourcetype? Well, in that case, we don’t even need to touch the journal at all. Using tstats, (tsidx stats), we can operate entirely within our summary data for much faster results.
In fact, this is the same concept behind datamodels, which allow you to compute large summaries with a defined set of fields, like url and user that you can use for faster searches later.
Alas, tstats isn’t a magic bullet for every search. The problem up until now was that fields had to be indexed to be used in tstats, and by default, only those special fields like index, sourcetype, source, and host are indexed. While you can customise this, it’s not the best idea, as it can cause performance and storage issues as Splunk has to spend more time computing bigger tsidx files to include all of your unique indexed values.
To go back to our VendorID example from earlier, this isn’t an indexed field - Splunk doesn’t know about it until it goes through the process of unzipping the journal file and extracting fields.
This has always been a limitation of tstats. Its was limited to two main uses:
Simple searches over default fields (index, sourcetype, etc)
Configuring datamodels in advance for known fieldsets
It wasn’t possible to use custom fields in your aggregations. In Splunk v7, you can use TERMs as bloomfilters to select data - | tstats summariesonly=t count where index="test_data" TERM(VendorID=1043) by sourcetype - but not in the by clause.
The solution is here with PREFIX
With this background, we’re finally ready to dive into why I think PREFIX is the most exciting new feature in Splunk v8. PREFIX solves these issues by letting you specify an indexed field syntax on the fly.
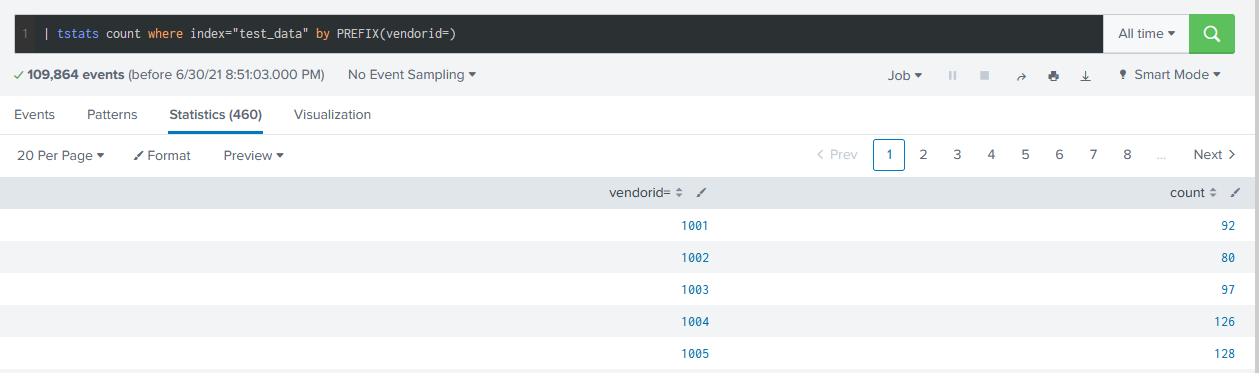
The data we need has been in the tsidx file all along, but Splunk didn’t know that it was actually a field we could use. If we could just tell Splunk that VendorID=1043 actually specifies a key-value pair, we could use it just like the indexed fields (index::test_data) or pre-configured datamodel fields (user::tyler), without any prior setup. To illustrate, we can now finally group by VendorID simply by specifying the format we expect. The syntax we use is PREFIX(vendorid=), but this could equally be any raw value separated by a minor breaker.
Yay!
Nothing in this life is perfect
Unfortunately, there’s still a few scenarios where PREFIX can’t be used. It requires key-value pairs to be contained within major breakers (like a space or |), with only a minor breaker separating them (like = or :.) This means that the below examples sadly aren’t applicable:
field: value -> the major separator here (space) means these terms are indexed separately.
"field":"value" -> the quote marks are major separators, also meaning PREFIX can’t be used.
field=value1|value2 -> | is a major breaker, so using PREFIX(field=) would only give you value1
While this does exlude JSON data and a few others, a lot of common formats like CEF and Splunk’s built-in collect’s raw option for summary indexes work perfectly.
In the right situations, PREFIX can give you a massive performance boost to your searches, and adds a lot of flexibility to the potential of tstats. While Splunk 8 has been out for over a year now, I still hope this has been useful to surface a power user feature that isn’t always talked about in the marketing materials.